Batching allows to you handle pagination scenarios on your data source.
Batching - large data sets
The primary reasons for batching are:
- When performing tasks like data migrations or other operations that deal with large amounts of data it is not possible to load the data in its entirety in memory.
- When working with APIs, there are often limits placed on the nuber of records an API endpoint will fetch in a single call.
- From a speed perspective, it is much faster to call an endpoint once and fetcg 100 records of data than to call an endpoint 100 times fetching one record at a time.
Blocks that support batching
All blocks can be used within a batch loop. The following blocks initiate a batch loop. The following blocks offer batching.
- HubSpot Read
- SQL (select)
- REST
- File (read)
- Data Store (read)
- Memory Store (read)
- Airtable
- Javascript
Block settings for Batching
Most Blocks that support batching have a checkbox option indicating you want to batch process records. You will then be able to se
- Batch Size - the number of records to read
- Max Iterations - the number of iterations or loops to perform between the Block and the corresponding Batch End block. Important : if you set Max Iterations to 0, then it will iterate until there is no more data to fetch.
Batch End Block
For all batching enabled Blocks, you must use a Batch End Block to mark the point at which execution should loop back to the originating Block.
You will get a Flow error if you fail to provide a Batch End Block.
Example
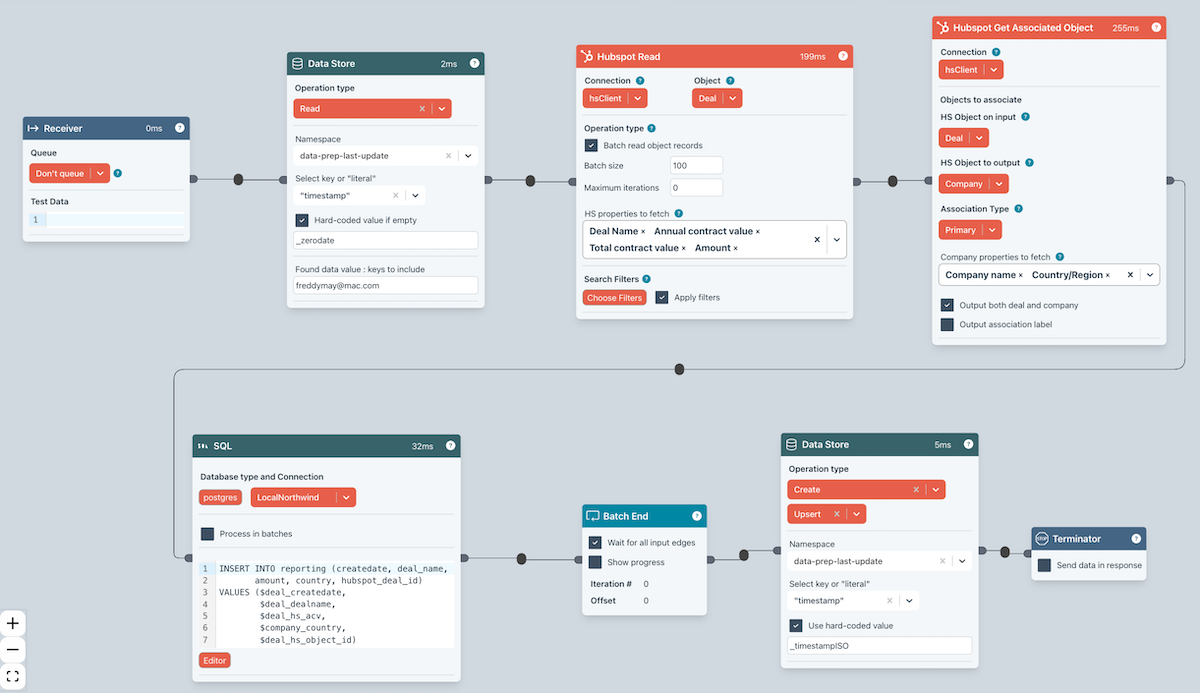
- The HubSpot Read block reads batches of 100 Deals from HubSpot.
- It then gets associated Companies
- And writes the resulting data to a database table.
- The key thing is the Batch End block. This loops back to the HubSpot Read block until there is no more data to fetch.
Example - Javascript
The Javascript Block also supports batching from your code. Refer to the Javascript Block for more details.