Feature summary
Below is a quick summary of Ziggy's key features.
Flow
Ziggy provides a canvas where you design Flows, which are made up of interconnected Blocks.
A key concept of Ziggy is to make communication with target Platforms as easy as possible. The Hubspot blocks are an excellent example of this.
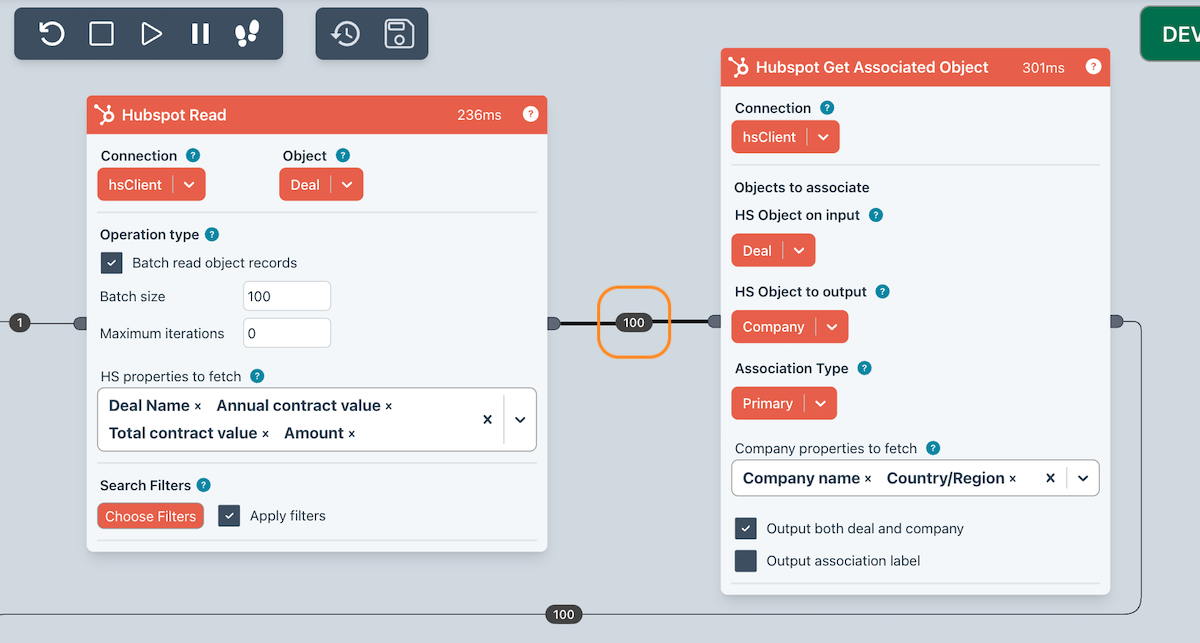
The Flow shown below is a good example of this.
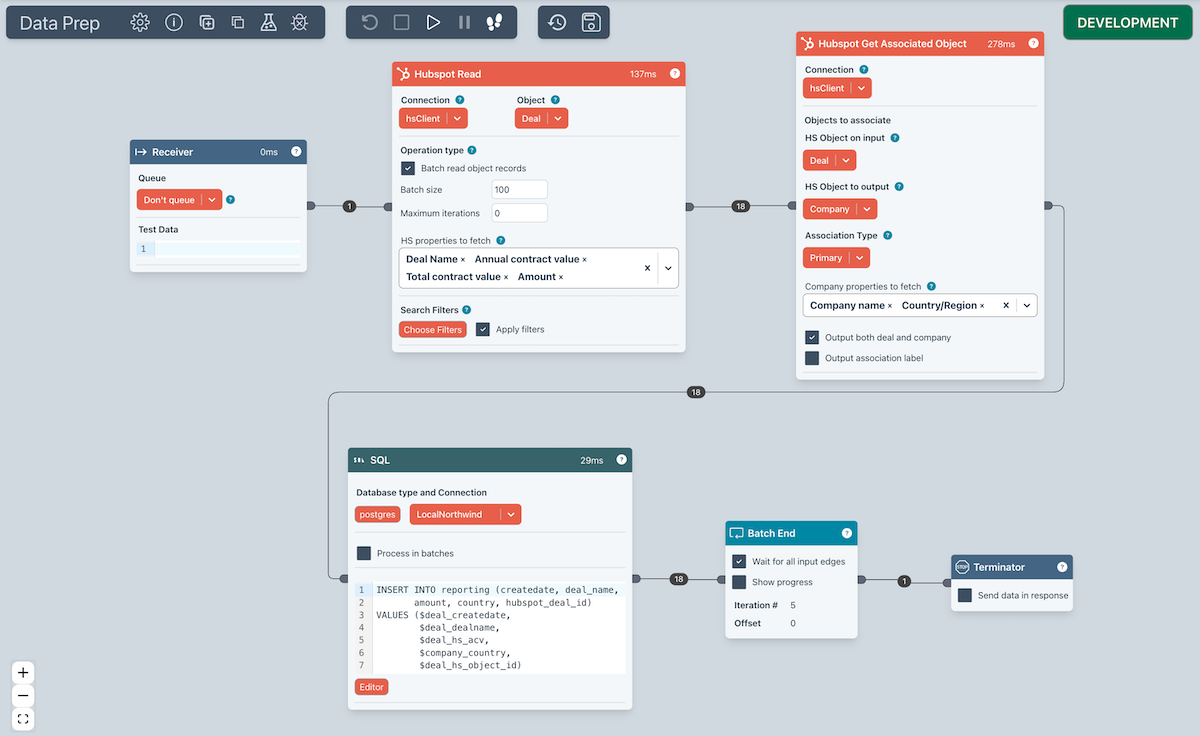
- Read in all Hubspot Deals (in batches of 100). There is a Filter applied to only take deals with a value of > $1000. A few Hubspot properties are retrieved.
- Get the associated Companies using a specific association type and fetches the specified Company properties.
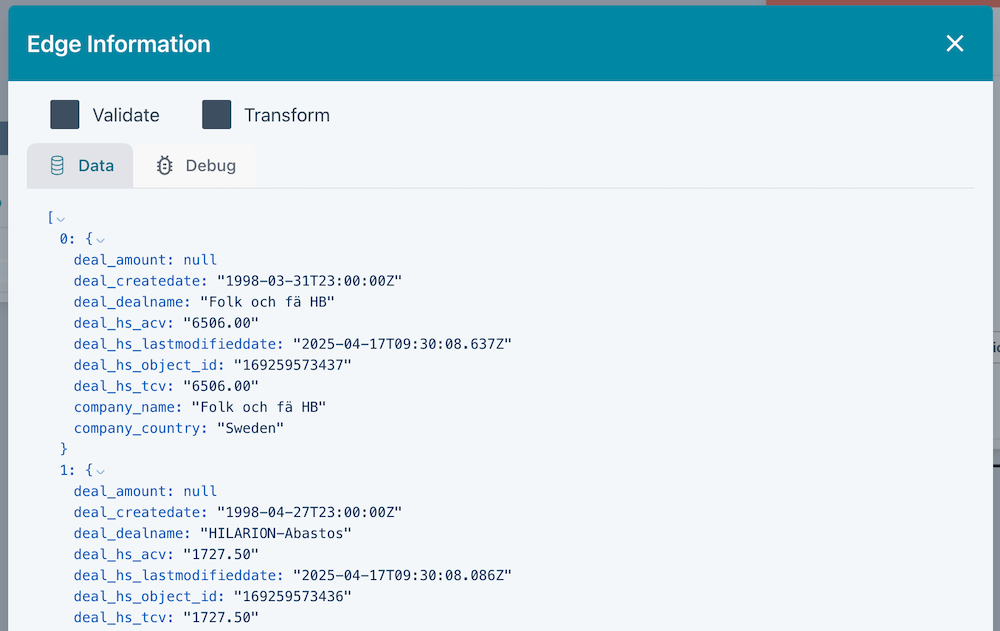
- Writes the combined Deal and Company information to the output edge (an example is shown below)
- Writes the data to a SQL database table.
{
deal_amount: null,
deal_createdate: "1998-04-15T23:00:00Z",
deal_dealname: "Königlich Essen",
deal_hs_acv: "2160.00",
deal_hs_lastmodifieddate: "2025-04-17T09:30:06.997Z",
deal_hs_object_id: "169335052481",
deal_hs_tcv: "2160.00",
company_name: "Königlich Essen",
company_country: "Germany"
}
Core Blocks
Below are a few of our commonly used Blocks.
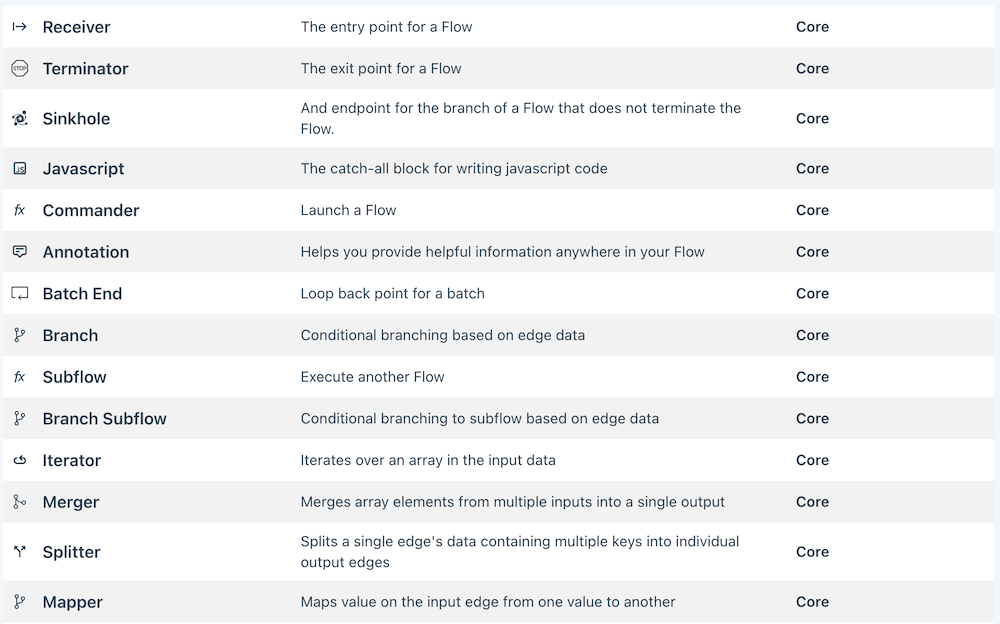
Utility Blocks
The perform more complex tasks such as:
- Writing CSV/JSON data to files on S3, SFTP etc.
- Writing to and reading from databases and data warehouses.
- REST calls.
- Writing to and reading from Ziggy's key/value Data Store.

Custom Blocks
These platform specific blocks, designed to simplify interactions with any target platform. Below are some of the HubSpot Custom Blocks.

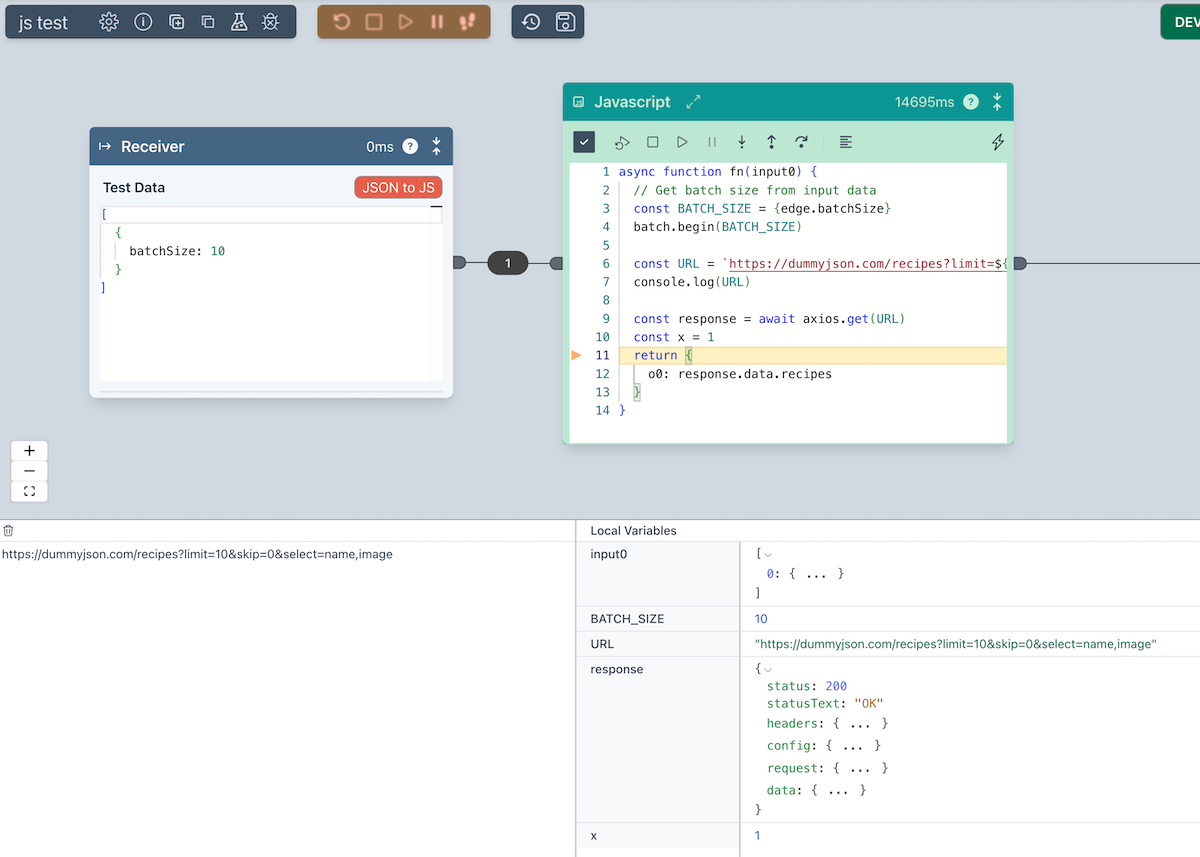
Javascript Block
The Javascript Block is a very flexible Block. It is perfect for dealing with any edge case or managing complex custom transformations.
- Call whitelisted NPM modules
- Integrated code debugger
- AI Assistant that is tightly integrated into the Ziggy Flow architecture. Great for non-developers wanting to do things you'd otherwise need a developer for.
Flow Debugger
Ziggy provides a comprehensive Flow Debugger. You can inspect data and view logs.
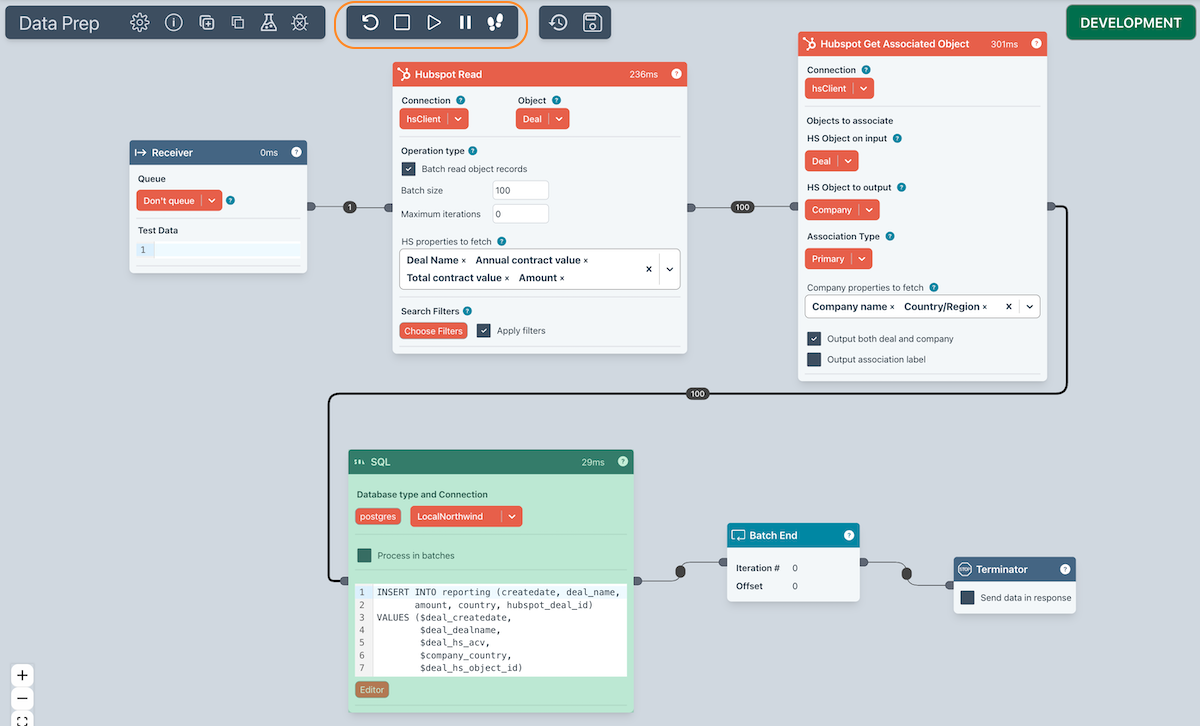
Data Inspection
You can inspect data at any point in your Flow by clicking on the edge "bubble". This will show you the first few records that have passed through that edge.
You can also inspect data by right-clicking on an edge and selecting "Inspect Data". This will show you a paginated view of the data.
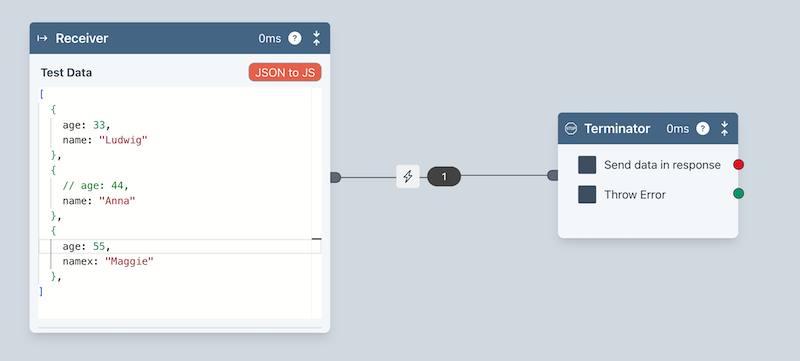
AI Edge Assistant
The AI Edge Assistant is a very powerful AI supported means of transforming, validating and mapping. It can even write failed validations to Ziggy's data store for processing later.
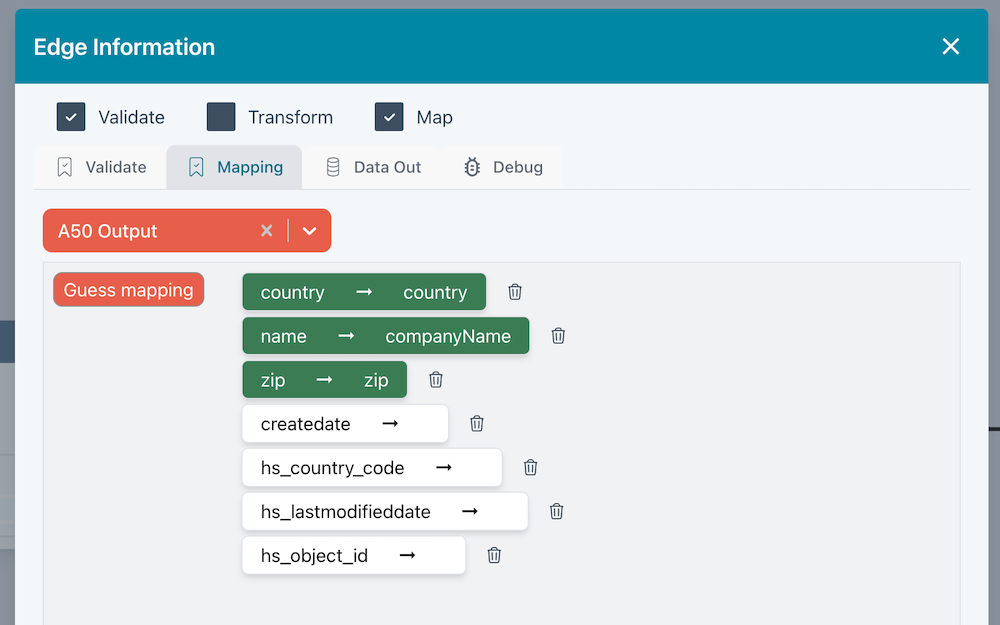
Edge Validation, Transformation and Mapping
You can validate, transform and map data on edges. This is useful for ensuring data quality and transforming data as it flows through your Flow.
Edge Transformation
You can also transform data on edges using Javascript. This is useful for more complex data transformations.
Subflows
You can create Subflows to organize your Flow and reuse common patterns. Subflows can be called from other Flows and can accept parameters.
RBAC User Management
Ziggy has a comprehensive Role Based Access Control system, supported by Teams and direct assignments for Flows, Connections, Secrets, Schedules and Messaging Items.
Execution History
Ziggy keeps a comprehensive Flow Execution History. You can view the results of previous executions and debug issues. You have full control of when and whether data persists.
Batching
Ziggy can process data in batches to improve performance and control memory usage.
Rate Limiting
Ziggy User Queues let you specify rate limits that protect against overage when using 3rd party platforms, or simply to dlow things down at strategic points in a Flow.
Performance Tuning
Ziggy is designed to be highly performant but give you full control over the important aspects of performance tuning.
- Max Concurrent Flows - how many Flows can run simultaneously. The ideal value depends very much on the nature of the Flows you are running.
- System Queue - if Max Concurrent Flows is exceeded then they are placed in an in-memory queue. You can specify the size of this queue.
- Overflow Queue - if the system queue is exceeded, further Flow execution requests are placed in a database overflow queue.
- User / Rate Limiting Queues - these are also tunable in a similar way.
The benefit of this approach is that you can extract the best possible performance without overloading the system or the memory queues.
All relevant values can be monitored in the System Monitor.
Load Testing
To help you with performance tuning, we provide a Load Testing option that lets you run large number of flows at any specified rate. The test results show clearly how key indicators are effected.
Alerts and Logging
Ziggy provides comprehensive logging and alerting capabilities. You can set up alerts for Flow failures and monitor Flow performance.
Secrets Management
Ziggy provides a secure way to store and manage secrets such as API keys and database passwords.
Connections
Ziggy provides a way to define and manage connections to external systems such as databases and APIs.
Data Store
Ziggy provides a fast, local key/value Data Store that can be used to store data for a variety of purposes. The Data Store Block provides access.
Memory Store
Ziggy provides an in-memory store that can be used to store data during Flow execution.
Commander
Commander is Ziggy's command-line interface that allows you to manage Flows, connections, and other resources.
Development and Production Modes
Ziggy provides separate development and production modes to ensure safe testing and deployment of Flows.
Scheduler
Ziggy provides a built-in scheduler that allows you to run Flows on a schedule.
Deployment
Ziggy is very easy to deploy. It is a simple Docker Container that always runs in a private server on the infrastructure of your choice. It normally runs just fine on a $12 per month AWS EC2 Instance (or equivalent on Azure etc.).
As a result you have full control over performance and security.
Data Transfer
Ziggy provides efficient data transfer capabilities for moving large amounts of data between systems.
Source Code
Ziggy's source code is available upon request.