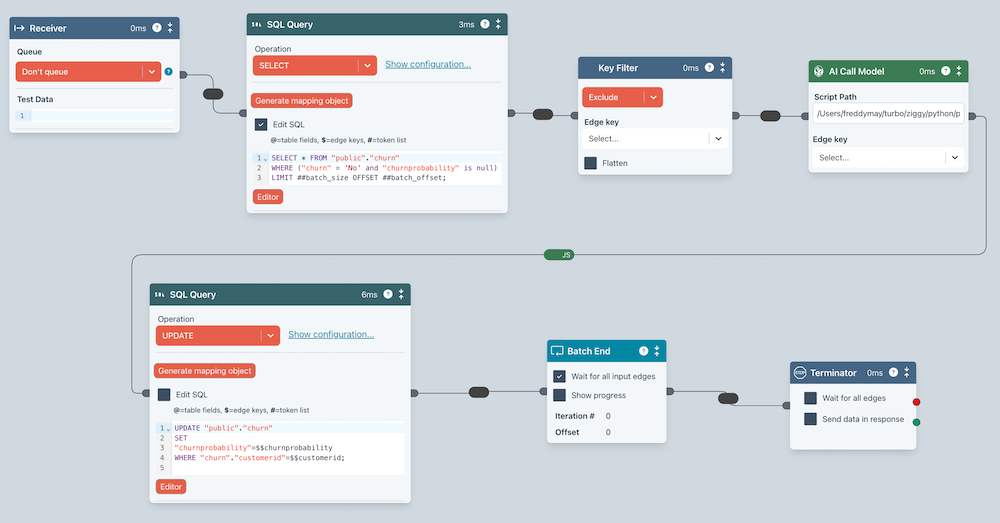
Ingestion Flows
If you already have data that's read to go from a search point of view, then you can ignore this.
However, if you want to make less than ideally searchable data highly searchable, then you can use an ingestion Flow.
Bulk Ingestion
If you need to ingest data for the first time, then you will need to run a Flow that ingests the required data. This data can come from anywhere and will typically end up in an Elastic Index, a database or data warehouse.
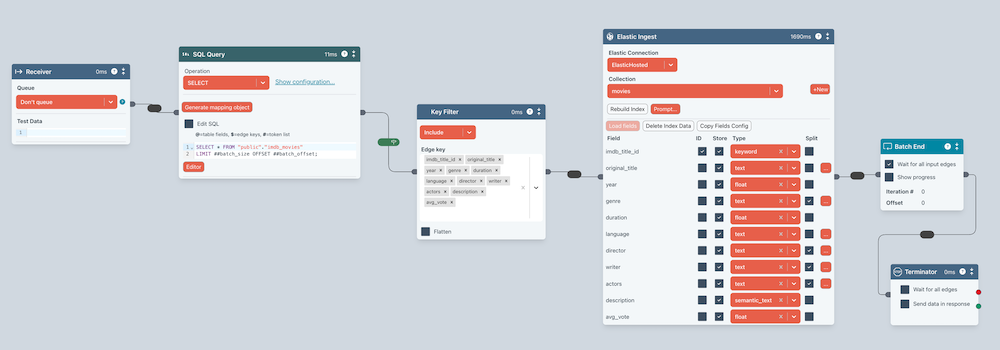
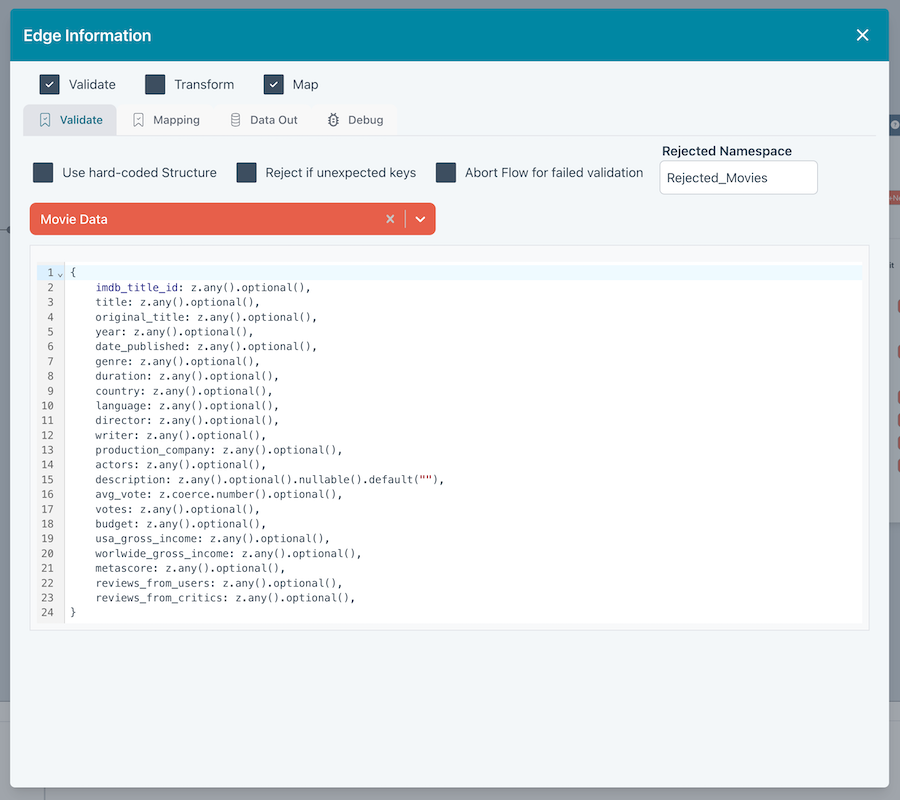
These Flows can perform validations, transformations and mappings of any complexity.
If you have large quantities of data, then Ziggy is very efficient at batch processing to avoid system overload and avoid API rate limits. From this point on, however, you may well want to perform incremental updates.
Incremental Ingestion
You can configure Ziggy Flows that are triggered by changes in data in any 3rd party system. This will often be one of the following.
- WebHooks - a 3rd party platform passes data to a Flow when data changes at the record level.
- Database Trigger
- API Call - any platform can call a Flow and pass over data to updare in the searchable data store.
- Scheduled - Ziggy has an integrated Scheduler that can trigger a Flow. From the Flow you could load data from an SFTP Server, run a database query with a data filter to fetch records update since the last fetch etc.